
🧬 The Algorithmic Apothecary
AI Frontiers in Pharmaceutical Innovation
Old cures sleep unread —
Silicon minds, wide awake,
Unlock the dark shelf.
With every article and podcast episode, we provide comprehensive study materials: References, Executive Summary, Briefing Document, Quiz, Essay Questions, Glossary, Timeline, Cast, FAQ, Table of Contents, Index, Polls, 3k Image, Fact Check, Comic and
Street Art at the very bottom of the page.
Soundbite
Trailer
Essay
There is a law in pharmaceutical science that most people have never heard of, and it is quietly devastating. It works exactly like Moore’s Law — that familiar rule that computing power doubles every two years while cost halves — except that it runs in reverse. Scientists named it Eroom’s Law, spelling Moore’s backwards as a kind of dark inside joke. Since 1950, the number of new drugs approved per billion dollars spent on research and development has been cut in half roughly every nine years.
Think about what that actually means. We have decoded the entire human genome. We have built robotic laboratories capable of running thousands of experiments simultaneously. We understand cellular biology at a level that would have looked like wizardry to a physician in 1960. And yet, for all that accumulating brilliance, the machine designed to save lives is producing less and less.
It costs an average of $2.6 billion and ten to fifteen years to bring a single new drug to market. Somewhere around 90 percent of drug candidates that enter human clinical trials fail — not because the science behind them was bad, but because the human body is not a petri dish and not a mouse. It is a turbulent, interconnected ecology of trillions of cells, and a molecule that works beautifully in a lab can be destroyed by stomach acid, blocked at the blood-brain barrier, or, worse, trigger a cascade of unintended consequences somewhere the researchers weren’t watching.
The real cruelty of the broken model is not what it costs pharmaceutical giants. It is what it costs patients. If a disease affects fewer than 50,000 people globally, the economics of traditional drug discovery make developing a cure essentially impossible. The math simply doesn’t work. Millions of people with rare, complex, or neglected conditions are not failing to be cured because we lack the science. They are failing to be cured because we lack the system.
Something is changing, though. And the change is stranger and more hopeful than most people realize.
It starts in a library in Chicago in 1986, with a researcher named Don Swanson, a stack of paper index cards, and a hunch that science was talking to itself without knowing it. Swanson theorized that what he called undiscovered public knowledge was hiding in plain sight — scattered across thousands of papers that had never cited one another, each one holding a piece of a puzzle that no single human brain could assemble. By manually cross-referencing papers on Raynaud’s disease — a circulatory condition that causes the fingers to turn white in cold — with unrelated nutritional science papers on fish oil, he constructed a chain of biological logic: fish oil lowers blood viscosity; high blood viscosity drives Raynaud’s symptoms; therefore, fish oil might treat Raynaud’s. He published the hypothesis without ever running a single experiment. Clinical researchers later proved him correct.
He had, essentially, invented the intellectual architecture of what AI does today. He just had to do it on foot, walking between stacks in a university library.
Now imagine giving that same methodology to a system that can read every biomedical paper ever published.
The field is called TechBio, and it is a meaningful departure from the biotech model most people picture when they imagine drug discovery — the scientist in a white coat, pipetting clear liquids into petri dishes, working from a hypothesis formed through years of painstaking reading and intuition. TechBio is data first. It is industrialized. It teaches machines to build knowledge graphs — three-dimensional webs containing millions of biological concepts and billions of verified relationships extracted from the literature — and then traverse those webs to find connections no single human lifespan could locate.
The results are already rewriting the economics. A company called InSilico Medicine used generative AI — two neural networks locked in continuous debate, one imagining new molecular structures, the other checking them against the laws of physics and chemistry — to identify a drug candidate for a devastating lung disease in 18 months, at a cost of $2.6 million. The traditional equivalent takes four and a half years and hundreds of millions of dollars.
But there is a deeper problem that pattern-matching, however sophisticated, cannot solve. Scientific breakthroughs at the hardest edge of medicine require more than connecting node A to node B. They require intuition. They require the ability to form entirely new hypotheses about why a biological system is behaving the way it is. They require something that looks, uncomfortably, like thinking.
In May 2026, Google DeepMind published a paper in Nature describing a system called Co-Scientist that attempts to answer that challenge. It is not a chatbot. It is not a search engine. It is a coalition of specialized AI agents — a generator, a reflector, a ranker, an evolver, a meta-reviewer — coordinated by a supervisor that assigns tasks non-linearly, running agents in parallel, managing a continuous tournament of ideas. Hypotheses are ranked using the same ELO mathematics that orders human chess grandmasters. The weakest arguments are eliminated; the strongest are refined and merged.
And critically — because the hallucination problem in large language models is real and potentially catastrophic when applied to physical science — the system spends the majority of its computational resources not on generating ideas but on verifying them against external databases of actual molecules and protein structures, grounding the textual hypotheses in physical reality before any human sees them.
The real-world results are striking. At Stanford, Gary Peltz asked Co-Scientist to find a way to halt the scarring mechanism in liver fibrosis. The AI identified an overlooked existing drug. When Peltz tested it on actual liver cells, it blocked 91 percent of the scarring-linked response on the first pass.
At MIT, Ritu Raman used Co-Scientist to advance her work on ALS. She described it as working with a genuine intellectual collaborator — not a tool that executed her instructions, but a partner that identified a structural weakness in her own hypothesis and, rather than filling the gap with a guess, explicitly prompted her to bring in a human RNA specialist she had not thought to consult.
At Harvard, Omar Abudeya, researching epigenetic reprogramming, said using Co-Scientist felt like having a team of 50 colleagues. His data analysis time collapsed from months to days.
There is a plot twist worth pausing over. For decades, pharmaceutical companies have been building dense thickets of defensive patents — hundreds of secondary filings around a single core drug, designed to keep generic competitors out of the market. These thickets are widely criticized as anti-competitive, as a driver of artificially high drug prices. They are a fortress of legal obstruction.
But to receive those patents, companies must disclose their data. They must provide experimental evidence for every claim. Hidden inside thousands of pages of dense legal language are records of hundreds of abandoned chemical variations — molecules that failed for the original target, or showed unexpected activity against a completely different biological pathway the company had no commercial interest in pursuing.
To a human reader, a pharmaceutical patent thicket is an impenetrable legal nightmare. To Co-Scientist, which can hold a million tokens of context and read 50 patents simultaneously, it is a treasure map. The very structure designed to hoard medical knowledge becomes the dataset that liberates new discoveries.
Eroom’s Law described a world in which better tools somehow produced worse outcomes — a maddening inversion of all reasonable expectation. The corrective is not simply more computing power applied to the old model. It is a different model entirely: one that treats the accumulated library of human biomedical knowledge not as a record of what has been tried, but as raw material for what might yet be found.
We are not waiting for new cures to be invented. In many cases, we are waiting to find the ones we already have.
The warehouse is full. We finally have the flashlight.


Link References
Co-Scientist: A multi-agent AI partner to accelerate research — Google DeepMind
De novo design of high-affinity protein binders with AlphaProteo
AI in Pharma: 15 Startups Accelerating Drug Discovery | IntuitionLabs
Measuring AI ROI in Drug Discovery: Key Metrics & Outcomes | IntuitionLabs
AI drug repurposing technology landscape 2026 - PatSnap
molIEreVIS: exploring and interpreting the evidence behind drug repurposing predictions
How AI Is Compressing 10-Year Drug Discovery Timelines to 18 Months: The 2026 Biotech Revolution
Episode Links
Apple Podcast
Youtube
Available for broadcast on PRX
PRX Series: The Alchemy of Intelligence: When AI Meets the Molecular World
Other Links to Heliox Podcast
YouTube
Substack
PRX ( Public Radio Exchange)
Podcast Providers
Spotify
Apple Podcasts
Patreon
FaceBook Group
STUDY MATERIALS
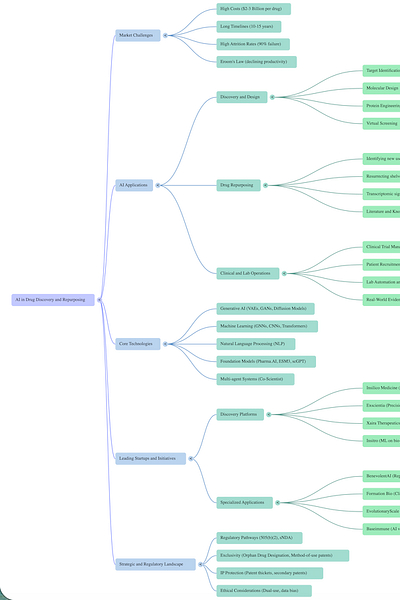
AI-Driven Transformation in Pharmaceutical R&D and Drug Repurposing
Executive Summary
The pharmaceutical industry is undergoing a fundamental strategic shift from “heroic, high-stakes discovery” to systematic, data-driven reinvention. Traditional drug development is currently hampered by “Eroom’s Law”—a phenomenon where R&D productivity halves every nine years, resulting in average costs of $2.6 billion and timelines of 10 to 15 years per approved drug. In response, a surge of artificial intelligence (AI) startups and computational platforms is attempting to “demultiply the axes of discovery.”
Key takeaways from current industry analysis include:
The Rise of AI Startups: Since 2023, hundreds of AI-focused biotech firms have emerged. High-profile entities like Xaira Therapeutics (launched with $1B in 2024) and the merger of Recursion and Exscientia in 2025 signify massive capital concentration in the sector.
Efficiency Gains: AI platforms have demonstrated the ability to shorten iterative chemistry cycles from 4–5 years to approximately 15 months (Exscientia) and reduce the number of compounds requiring synthesis by up to 90%.
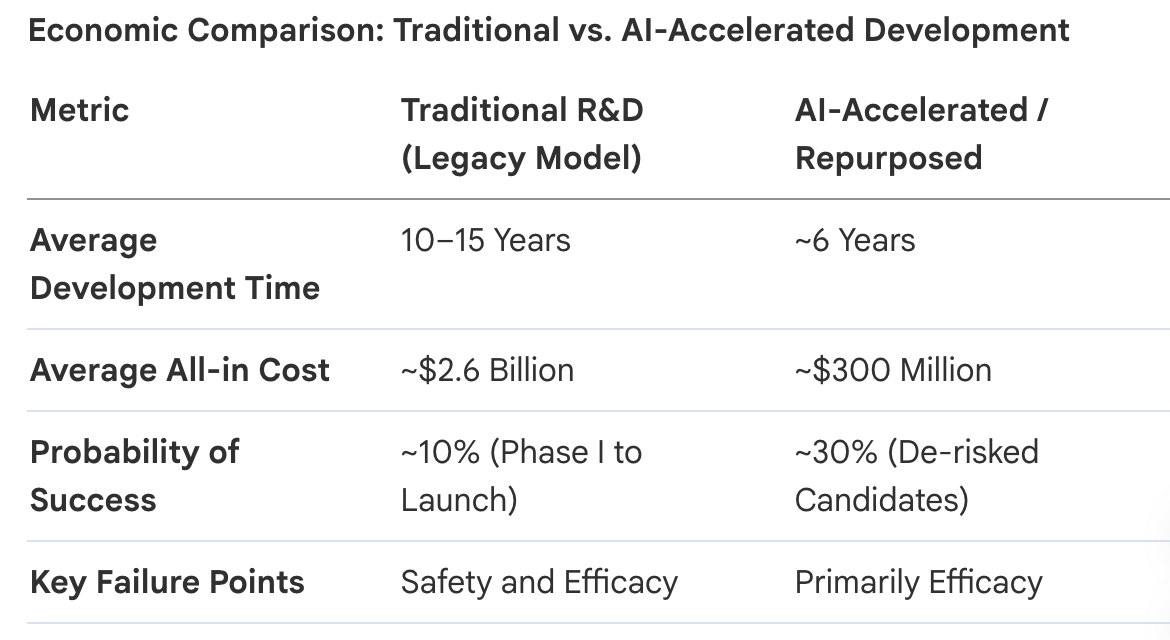
The Repurposing Revolution: Systematic computational screening of existing drugs for new indications—drug repurposing—now accounts for approximately 30% of newly marketed drugs in the U.S. This pathway reduces costs to ~$300 million and timelines to roughly 6 years.
Clinical Proof-of-Concept: In June 2025, Insilico Medicine reported the industry’s first proof-of-concept clinical validation for an AI-designed drug, Rentosertib, which showed significant improvement in lung function for Idiopathic Pulmonary Fibrosis (IPF) patients in Phase IIa trials.
Structural Risks: Despite these advances, as of mid-2025, no AI-discovered drug has yet reached the market. The field faces challenges in data quality, regulatory hurdles, and a high attrition rate in “hard” repurposing (moving drugs across different therapeutic areas).
--------------------------------------------------------------------------------
I. The Crisis in Traditional Pharmaceutical R&D
The traditional “bench to bedside” model is increasingly viewed as economically unsustainable due to three primary factors:
Extreme Attrition: Roughly 90% of drug candidates entering clinical trials fail. Only ~12% of novel compounds move from Phase I to approval.
Escalating Costs: Capital costs for a single success average $1.3 billion, but the total “all-in” cost per approved drug reaches $2.6 billion when accounting for the cost of portfolio failures.
Extended Timelines: Developing a novel chemical entity (NCE) takes an average of 12–15 years, with only ~30% of molecules cleared in Phase I reaching Phase III.
--------------------------------------------------------------------------------
II. Leading AI Startups and Industry Movements
The sector is defined by a diverse array of startups targeting different bottlenecks in the R&D pipeline.
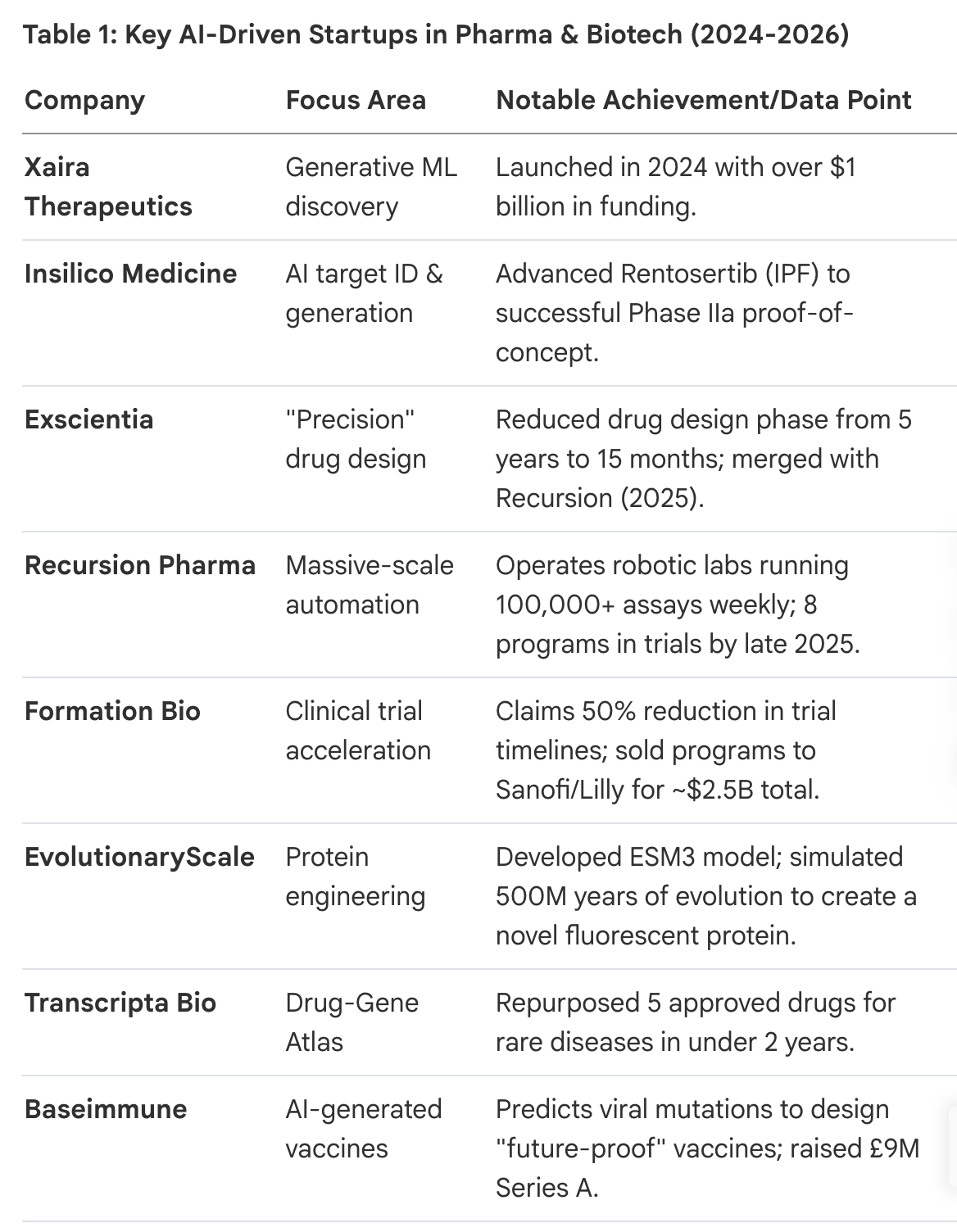
--------------------------------------------------------------------------------
III. Strategic Framework: Drug Repurposing
Drug repurposing involves identifying new therapeutic uses for compounds that have already cleared at least one stage of human evaluation.
Economic and Success Metrics
Cost Advantage: Repurposing costs approximately 300million∗∗perdrug,comparedto∗∗2.6 billion for novel discovery.
Probability of Success: The probability of market approval for a repurposed drug is approximately 30%, triple the success rate of novel entities.
“Soft” vs. “Hard” Repurposing:
Soft Repurposing: Expanding use within the same therapeutic area (e.g., breast cancer to ovarian cancer) has a 67% success rate.
Hard Repurposing: Moving a drug to a completely different therapeutic area has a success rate as low as 9% for failed drugs and 33% for approved ones.
The Role of Intellectual Property (IP)
Repurposing necessitates a “secondary patent strategy” because composition-of-matter patents are often expired or nearing expiration.
Exclusivity Towers: Companies use method-of-use, formulation, and dosing regimen patents to build new exclusivity.
Orphan Drug Designation (ODD): A critical tool for rare diseases, ODD provides 7 years of U.S. market exclusivity regardless of patent status.
Patent Thickets: Large firms build dense webs of secondary patents (e.g., AbbVie’s 250+ applications for Humira) to deter generic competition.
--------------------------------------------------------------------------------
IV. Technical Methodologies and the AI Roadmap
The transition from “serendipity to strategy” is powered by four generations of machine learning:
Generation 1 (2005-2015): Classical ML (SVMs, Random Forests) using hand-engineered molecular fingerprints.
Generation 2 (2015-2020): Deep Learning (CNNs and Graph Neural Networks) applied to raw molecular graphs, enabling better “scaffold hopping.”
Generation 3 (2020-2024): Transformer models (ESM series) and multi-modal integration of chemical, genomic, and clinical data.
Generation 4 (2024-Present): Biological Foundation Models (scGPT, scFoundation) and causal inference to predict cell-type-specific responses.
Key Computational Approaches
Disease-Centric: Using tools like the Connectivity Map (CMap) and LINCS to match drug-induced gene expression signatures against disease signatures to find “inverse” matches.
Target-Centric: Utilizing AlphaFold2 (200M+ protein structure predictions) for virtual screening and molecular docking.
Network Biology: The “Network Proximity Hypothesis” suggests that a drug is effective if its targets cluster in the same network neighborhood as disease-associated genes.
--------------------------------------------------------------------------------
V. Clinical and Economic Case Studies
1. Rentosertib (Insilico Medicine)
Mechanism: Novel TNIK inhibitor for Idiopathic Pulmonary Fibrosis (IPF).
Outcome: Phase IIa trial showed a mean lung function (FVC) improvement of +98.4 mL, compared to a -20.3 mL decline in the placebo group.
Efficiency: Discovered and designed in only 12–18 months, requiring the synthesis of only ~80 molecules.
2. Baricitinib (Eli Lilly/BenevolentAI)
Mechanism: Originally a JAK1/JAK2 inhibitor for rheumatoid arthritis.
AI Insight: BenevolentAI identified its effect on AAK1, a regulator of viral entry, in early 2020.
Outcome: Repurposed for COVID-19 at pandemic speed because Phase I safety data was already established.
3. Sildenafil (Pfizer)
Evolution: Originally an angina candidate, repurposed as Viagra (erectile dysfunction), then as Revatio (Pulmonary Arterial Hypertension).
Strategic Impact: The Revatio program created a second “exclusivity tower” through ODD and PAH-specific dosing patents, reaching $400M in peak annual revenue even after the primary Viagra patents expired.
--------------------------------------------------------------------------------
VI. Current Challenges and Barriers
The Translation Gap: Fewer than 10% of prospective computational repurposing predictions generate a positive Phase II signal. The primary failure mode is inadequate target exposure in specific tissues at tolerable human doses.
Data Bias: Public databases (ChEMBL, DrugBank) are biased toward well-studied families like kinases and GPCRs, causing AI models to underperform on underexplored biology.
Label Arbitrage: Even with a valid method-of-use patent for a new indication, generic manufacturers can capture the market if physicians prescribe the original generic version off-label.
Regulatory Scrutiny: The FDA has shown a willingness to withdraw Accelerated Approvals if confirmatory Phase III trials fail, increasing the risk for oncology-focused AI programs.
--------------------------------------------------------------------------------
VII. Future Directions
The industry is moving toward “Precision Repurposing,” where AI identifies molecularly defined patient subgroups likely to respond to a known drug. This involves:
Companion Diagnostics: Pairing a drug with a biomarker test to create a more defensible IP position.
Single-Cell Resolution: Integrating the Human Cell Atlas to move from “bulk” tissue analysis to cell-type-specific drug perturbation predictions.
Federated Learning: Utilizing privacy-preserving frameworks like PCORnet to mine hundreds of millions of Electronic Health Records (EHR) for repurposing signals without transferring patient data.
Quantum Computing: A horizon technology (estimated for 2030s) that may eventually allow for full electronic-structure resolution of drug-target binding.
Quiz & Answer Key
Instructions: Answer each of the following ten questions in 2–3 sentences.
How do the costs and timelines of de novo drug discovery compare to those of drug repurposing?
Explain the concept of “Eroom’s Law” as mentioned in the text.
What is the difference between “soft” and “hard” drug repurposing?
How does the 505(b)(2) NDA pathway facilitate the drug repurposing process?
Describe the role of the Connectivity Map (CMap) in disease-centric repurposing.
What is a “patent thicket,” and how does it serve as a strategic barrier to entry?
Why is “Time-split validation” considered a critical methodological standard for evaluating AI repurposing models?
How did Baricitinib’s established safety profile impact its repurposing for COVID-19?
Define “Markush Structure” and its utility in pharmaceutical patents.
What were the significant findings of Insilico Medicine’s Phase IIa trial of Rentosertib for Idiopathic Pulmonary Fibrosis (IPF)?
--------------------------------------------------------------------------------
Answer Key
Costs and Timelines: De novo discovery typically costs approximately $2.6 billion and takes 10–15 years, with a success rate of about 10%. In contrast, drug repurposing averages a cost of $300 million and a timeline of 6 years, with a success rate closer to 30% because it leverages existing safety and toxicology data.
Eroom’s Law: This term describes the phenomenon where the number of new drugs approved per billion dollars of R&D spending has halved roughly every nine years. It is essentially “Moore’s Law” in reverse, highlighting the declining productivity and increasing expense of traditional pharmaceutical innovation.
Soft vs. Hard Repurposing: Soft repurposing involves expanding a drug’s use within the same therapeutic area (e.g., moving from breast cancer to ovarian cancer), which has higher success rates. Hard repurposing involves finding entirely new uses in different disease settings (e.g., a cardiovascular drug for a neurological condition), which is more ambitious but significantly riskier.
505(b)(2) NDA: This regulatory pathway allows an applicant to rely on existing safety and efficacy data from previously approved “listed drugs” or published literature. It streamlines development by reducing the need for new Phase I safety studies, allowing sponsors to move directly to Phase II or III.
Connectivity Map (CMap): CMap is a database of gene expression signatures produced by thousands of small molecules. In disease-centric repurposing, researchers look for a drug that induces a transcriptional profile opposite to the disease’s signature, suggesting the drug can pharmacologically reverse the disease state.
Patent Thicket: A patent thicket is a dense web of overlapping intellectual property rights (secondary patents covering formulations, manufacturing, or new uses) built around a single drug. It deters generic competition by creating a litigation landscape that is too costly and time-consuming for competitors to navigate.
Time-split Validation: This standard requires an AI model to be trained on drug-disease associations known before a specific date and then tested on those discovered afterward. It prevents “data leakage,” ensuring the model can truly predict novel associations rather than simply recalling information it has already seen.
Baricitinib for COVID-19: Because Baricitinib already had a full safety data package from its rheumatology indication, it was able to bypass Phase I testing during the pandemic. This enabled the repurposing program to move directly into Phase III trials under NIAID sponsorship, reaching patients much faster.
Markush Structure: This is a claim-drafting convention that allows a patent to define a broad class of related molecules using a common chemical scaffold with variable components at specific positions. It allows inventors to protect a wide family of compounds without listing every single individual molecule.
Rentosertib Findings: The GENESIS-IPF trial showed that Rentosertib (a TNIK inhibitor) was safe and manageable for patients. Most significantly, patients receiving a 60 mg dose showed a mean lung function improvement of +98.4 mL (measured by Forced Vital Capacity), compared to a decline in the placebo group, marking a major milestone for AI-discovered drugs.
Essay Questions
Instructions: Select one of the following topics and develop a comprehensive essay based on the source context.
The Economic Imperative of Repurposing: Analyze how the pharmaceutical industry uses drug repurposing as a countermeasure to “Eroom’s Law.” Discuss the financial advantages, the role of de-risked assets, and how this strategy impacts the development of treatments for rare and neglected diseases.
The Evolution of AI Methodology: Discuss the four generations of machine learning in pharmaceutical R&D described in the text. Compare and contrast classical ML molecular descriptors with modern biological foundation models like scGPT and scFoundation.
Intellectual Property and Lifecycle Management: Examine the strategic use of secondary patents and “evergreening” in the pharmaceutical sector. Evaluate the legal hurdles of novelty and non-obviousness that repurposed drugs must overcome, and the role of “unexpected results” in securing new patents.
The Regulatory Landscape: Compare the various regulatory incentives available for repurposed drugs, including the 505(b)(2) pathway, Orphan Drug Designation (ODD), and Breakthrough Therapy Designation. How do these tools collectively influence a company’s commercialization strategy?
Precision Repurposing and the Future: Explore the convergence of computational repurposing with precision medicine. Discuss how single-cell genomics, the Human Cell Atlas, and federated learning are moving the field toward “N-of-1” repurposing tailored to individual patient biology.
Glossary of Key Terms
505(b)(2) NDA
A regulatory pathway allowing an NDA applicant to rely on safety and efficacy data not generated by the sponsor, often accelerating the approval of repurposed drugs.
AlphaFold2
A deep learning system developed by DeepMind that predicts the 3D structures of proteins; it has expanded the tractable target space for drug discovery.
AUPR
Area Under the Precision-Recall Curve; a metric used to evaluate AI models, particularly informative when positive data points are sparse.
Breakthrough Therapy Designation (BTD)
A process designed to expedite the development and review of drugs intended to treat serious conditions where preliminary clinical evidence shows substantial improvement over available therapy.
Eroom’s Law
The observation that drug discovery is becoming slower and more expensive over time, contrary to the trends seen in Moore’s Law for computer processing.
Evergreening
The practice of filing multiple incremental patents on a single drug (e.g., new formulations or doses) to extend the period of market exclusivity.
Federated Learning
A machine learning approach where models are trained on local data across multiple institutions without sharing raw patient-level data, ensuring privacy.
Graph Neural Networks (GNN)
A type of deep learning architecture that represents biological entities (genes, drugs, diseases) as nodes in a graph to predict their interactions.
Indication Expansion
The process of seeking regulatory approval to use an existing drug for a new disease or condition (also called “soft” repurposing).
Markush Group
A patent drafting technique used to claim a broad class of chemically related compounds by defining a common scaffold with variable side chains.
Mendelian Randomization
A causal inference method that uses genetic variants as proxies for environmental exposures to test drug repurposing hypotheses in human populations.
Orphan Drug Designation (ODD)
A status granted to drugs treating rare diseases (affecting <200,000 people in the US), providing seven years of market exclusivity and tax credits.
Paragraph IV Certification
A legal mechanism where a generic manufacturer challenges a brand-name drug’s patent by asserting that the patent is invalid or will not be infringed.
Pharmacophore Modeling
A computational method that abstracts the essential geometric and chemical features required for a molecule to bind to a specific biological target.
Polymorph
Different crystalline structures of the same active pharmaceutical ingredient; often the subject of secondary patents in lifecycle management.
Transcriptomics
The study of the complete set of RNA transcripts in a cell, used in “signature-matching” to find drugs that can reverse disease expression patterns.
Cast of Characters
1. The Strategic Context: Beyond Eroom’s Law
The biopharma industry is currently grappling with the terminal stage of Eroom’s Law—the observation that drug R&D becomes exponentially more expensive as technological progress accelerates. This innovation crisis is characterized by a legacy model where bringing a single molecule to market requires an all-in investment of ~$2.6 billion and a 10–15 year timeline, only to face a 90% attrition rate in the clinic. This “heroic discovery” model, predicated on serendipitous “hits,” is being structurally dismantled by AI-native firms that treat biology as a searchable, engineering-ready data space. By transitioning from manual trial-and-error to systematic, algorithmic pipelines, these pioneers are establishing new efficiency benchmarks that prioritize capital efficiency and predictive accuracy over sheer volume.
For institutional investors, this paradigm shift fundamentally reweights the risk-reward calculus. Moving from “discovery-centric” to “validation-centric” models allows for a “barbell” portfolio strategy: balancing high-risk novel assets with AI-de-risked platforms that offer higher probabilities of technical success. This transition signals a move away from binary “all-or-nothing” clinical bets toward a predictable manufacturing logic, fundamentally altering the valuation moats of the next-generation biopharma titans. As the industry moves from manual sifting to computational sieving, the focus is shifting toward the architects of these new molecular design platforms.
2. The Platform Architects: Designing Molecules from First Principles
The strategic importance of AI-native discovery platforms lies in their ability to navigate the nearly infinite chemical space using high-dimensional biological data. By moving beyond classical “fingerprint-based” machine learning to sophisticated Graph Neural Networks (GNNs), these firms can predict molecular behavior with a resolution that bypasses traditional wet-lab iterations.
Exscientia: A pioneer in “precision” AI design, Exscientia has demonstrated the ability to compress the iterative chemistry cycle from 5 years to just 15 months. By optimizing for “design-to-readout” speed, they reached lead candidates by synthesizing only 250 compounds, a massive reduction compared to the 5,000 typically required in legacy R&D.
Insitro: Leveraging a “Platform-as-a-Service” (PaaS) logic, Insitro applies ML to massive biological datasets to identify novel disease hypotheses. Their valuation inflection point is underscored by high-tier strategic partnerships with Eli Lilly and Bristol-Myers Squibb, signaling industry trust in their ability to find signals in complex metabolic and neurological data.
Recursion Pharmaceuticals: Recursion operates at a “supermarket” scale of automation, with robotic labs running 100,000+ assays per week. The late 2025 merger with Exscientia represents a landmark “Scale vs. Precision” strategic play, combining Recursion’s massive-scale data generation with Exscientia’s molecular design precision to dominate the discovery-stage moat.
Atomwise: Utilizing Convolutional Neural Networks (CNNs) for virtual screening, Atomwise applies deep learning to structural data to predict protein-ligand interactions, drastically accelerating the “hit” discovery phase for various pharmaceutical partners.
As these architects refine the design of small molecules through algorithmic precision, a new group of visionaries is emerging to treat biology itself as a programmable medium.
3. The Generative Visionaries: Biology as Code
Generative biology represents a strategic leap from searching nature to inventing it. By training foundational models on trillions of biological data points—encompassing protein sequences, structures, and single-cell transcriptomics—these firms can predict function and “write” novel proteins from first principles.
EvolutionaryScale: The launch of the ESM3 protein language model represents a “GPT-4 moment” for biology. Trained on 771 billion “widgets” (data points), ESM3 simulated 500 million years of evolution to create “esmGFP,” a novel fluorescent protein not found in nature. This proves that generative AI can bypass natural evolutionary constraints to engineer functional biomolecules.
Baseimmune: Strategically focused on “pre-emptive” vaccinology, Baseimmune uses AI to predict pathogen mutations before they emerge. This allows for the design of “updateable” vaccines, moving the timeline of vaccine development from months of wet-lab iteration to weeks of in silico prediction.
The emergence of biology foundation models, such as scGPT and scFoundation, is critical for reducing measurement noise and exploration costs. By enabling “virtual twin” simulations of cell-type-specific responses at single-cell resolution, these models allow researchers to prototype therapies in silico with high fidelity. This predictive power is now being applied to existing drug libraries to unlock hidden therapeutic potential.
4. The Systematic Alchemists: Masters of Drug Repurposing
Drug repurposing (repositioning) offers the most immediate path to capital efficiency by utilizing compounds that have already cleared human safety hurdles. The strategic distinction lies between “Soft” repurposing (indication expansion within a therapeutic area), which boasts a 67% success rate for approved products, and “Hard” repurposing (cross-therapeutic area), which sees a more sobering 9% success rate for failed drugs.
Insilico Medicine: In June 2025, Insilico achieved the industry’s first clinical proof-of-concept for an AI-discovered drug. Phase IIa results for Rentosertib (ISM001-055) in IPF showed a mean FVC improvement of +98.4 mL compared to a -20.3 mL decline in the placebo group, validating TNIK as a novel target identified via generative AI.
Transcripta Bio: Through its “Drug-Gene Atlas,” Transcripta captures the arbitrage between existing drug libraries and rare disease signals. They successfully moved 5 repurposed drugs into rare disease trials in under 2 years, a process that typically requires 5–8 years.
BenevolentAI: While AI accelerates the identification of the target-molecule fit, the 2023 termination of their eczema trial serves as a strategic warning: AI does not yet solve for the complexity of human systemic biology. The moat lies in validation, not just discovery.

To sustain these clinical movements, the industry relies on a suite of operational enablers to clear post-discovery bottlenecks.
5. The Operational Enablers: Automating the Lab and Trial
Strategic innovation must extend into the “Valley of Death”—the gap between discovery and commercialization. Operational enablers apply AI to trial logistics and laboratory workflows to capture higher margins through administrative speed.
Formation Bio: Operating with a PaaS-driven arbitrage model, Formation Bio acquires “orphaned” or undervalued academic assets and uses AI to reduce trial timelines by 50%. Their strategic signaling is evident in billion-dollar deals with Sanofi (€545M) and Eli Lilly (~$2B), proving that operational speed is a tradable currency in biopharma.
Autoscience: Building toward the “autonomous laboratory,” Autoscience raised a $14M seed in 2024. Their milestone of an AI-generated, peer-reviewed research model with minimal human input points to a future where hypothesis testing is continuous and automated.
Strateos (Synthace): By providing a “Lab OS,” these platforms allow robotic biology workflows to be programmed as code, optimizing protocol execution and reducing human error.
Furthermore, the use of “virtual twins” (e.g., Unlearn.AI) to simulate control arms using historical data is a critical de-risking tool. By reducing the number of human participants required, virtual twins slash the cost and duration of late-stage trials. This operational speed, however, is only sustainable when protected by the regulatory and legal “Gauntlet.”
6. The Strategic Guardians: Navigating IP and Regulatory Pathways
The “IP Gauntlet” is where AI-driven speed meets legal durability. For repurposed or AI-discovered assets, the 505(b)(2) NDA and Orphan Drug Designation (ODD) are the essential regulatory bridges that protect the $300M/6-year development economic model.
The Regulatory Pillars
505(b)(2) Pathway: The strategic “shortcut” for repurposed drugs. By relying on existing safety data from a “listed drug,” sponsors compress the path to Phase II, bypassing redundant Phase I safety trials.
Orphan Drug Designation: A critical valuation moat for rare diseases. ODD provides 7 years of market exclusivity and tax credits (adjusted to 25% following 2026 mandates), often generating pricing power that survives the expiration of original composition-of-matter patents.
Patent Thickets: To counter generic “label arbitrage,” firms utilize secondary patents (dosing, formulation, and method-of-use) to build defensive walls. While “evergreening” is criticized, it remains a necessary tool for protecting the ROI of repurposed assets.
The integration of regulatory science and AI is now a prerequisite for long-term commercialization, as it ensures that “label arbitrage” risk is mitigated early in the design phase.
7. Synthesis: The Future of the Pharma Landscape
The AI-biotech sector is transitioning from its “hype” phase into a period of rigorous “product-market fit” evaluation. As algorithmic tools become democratized, the competitive moat will shift from discovery to clinical validation and regulatory execution. Three takeaways define the future:
Validation-Centric Competitive Advantage: The ultimate winner is not the firm that generates the most “hits,” but the one that validates them fastest in human systemic biology.
Explainable AI (XAI): To gain regulatory and academic trust, firms must replace “black box” predictions with mechanistic rationales. XAI is the key to unlocking FDA approval for AI-derived targets.
“N-of-1” Precision Repurposing: The strategic endgame is the convergence of AI and personalized medicine—identifying the optimal, established drug for a single patient’s unique genomic profile in real-time.
In this new era, the “Cast of Characters” who successfully bridge the gap between algorithmic insight and clinical reality will define the next century of human health.

FAQ
1. Foundational Economics and Strategic Definitions
The pharmaceutical industry is currently executing a structural pivot to escape the gravitational pull of “Eroom’s Law”—the observation that drug discovery is becoming exponentially more expensive and less productive over time. For decades, the industry relied on “serendipitous” discovery, where new uses for drugs were found by accidental clinical observation. Today, this has been replaced by algorithmic pipelines. By using computational platforms to systematically interrogate millions of compound-indication pairs, firms are shifting from pure invention to systematic reinvention. This approach transforms the traditional R&D model into a data-driven search for value within existing chemical libraries, drastically reducing the “bench-to-bedside” duration and salvaging the industry’s R&D return on investment (ROI).
1.1. How does the economic profile of AI-driven drug repurposing compare to traditional de novo discovery?
The economic delta between creating a New Chemical Entity (NCE) and repurposing an existing asset is staggering. Repurposing leverages a compound’s existing human safety and toxicology data, allowing developers to bypass the most failure-prone early stages of research.

1.2. What are the critical distinctions between “Soft” and “Hard” drug repurposing?
Strategic success in repurposing is heavily dictated by “therapeutic proximity,” which determines the technical and commercial risk profile.
“Soft” Repurposing: Expanding a drug’s use within the same therapeutic area (e.g., testing a breast cancer drug for ovarian cancer). This has a high success rate of approximately 67% for approved products because the diseases often share molecular pathways.
“Hard” Repurposing: Identifying uses for a molecule in a completely different therapeutic area (e.g., moving a cardiovascular drug into neurology). The success rate drops significantly to 33% for approved products.
The Strategist’s View: From a portfolio management perspective, “Hard” repurposing must be viewed as an ambitious attempt at biological alchemy, requiring a higher risk-adjusted discount rate in valuation models. Conversely, “Soft” repurposing is a high-probability extension of known science that offers a more predictable ROI.
1.3. How does the “Failed Asset” library function as a strategic de-risked reservoir?
A “failed” drug is no longer viewed as a sunk cost, but as a de-risked asset. Compounds that failed Phase III for efficacy—but remained safe in humans—are the highest-value targets for repurposing. These assets possess a complete library of toxicology, pharmacokinetic (PK), and formulation data. Under 21 CFR 314.50(b), developers can leverage this existing data package to compress timelines by 5 to 7 years, jumping directly into Phase II efficacy trials for a new indication. This regulatory distinction allows for a “repositioning” strategy that is far more capital-efficient than starting with an uncharacterized NCE.
While the economic advantages of repurposing are clear, the realization of this value depends on the execution capabilities of a new generation of AI-native biotech firms currently scaling their infrastructure.
2. The Startup Landscape: 15 Leaders Reshaping R&D
The AI-biotech sector has entered an intensive “searching for product-market fit” phase. While the technology is maturing, the scale of capital investment signals a total build-out of AI-native infrastructure, highlighted by the massive $1 billion launch of Xaira Therapeutics in 2024. These firms are not merely tools for existing pharma; they are end-to-end discovery engines.
2.1. Who are the leading AI drug discovery platforms and what are their specific breakthroughs?
The following table summarizes 15 representative leaders in the field:
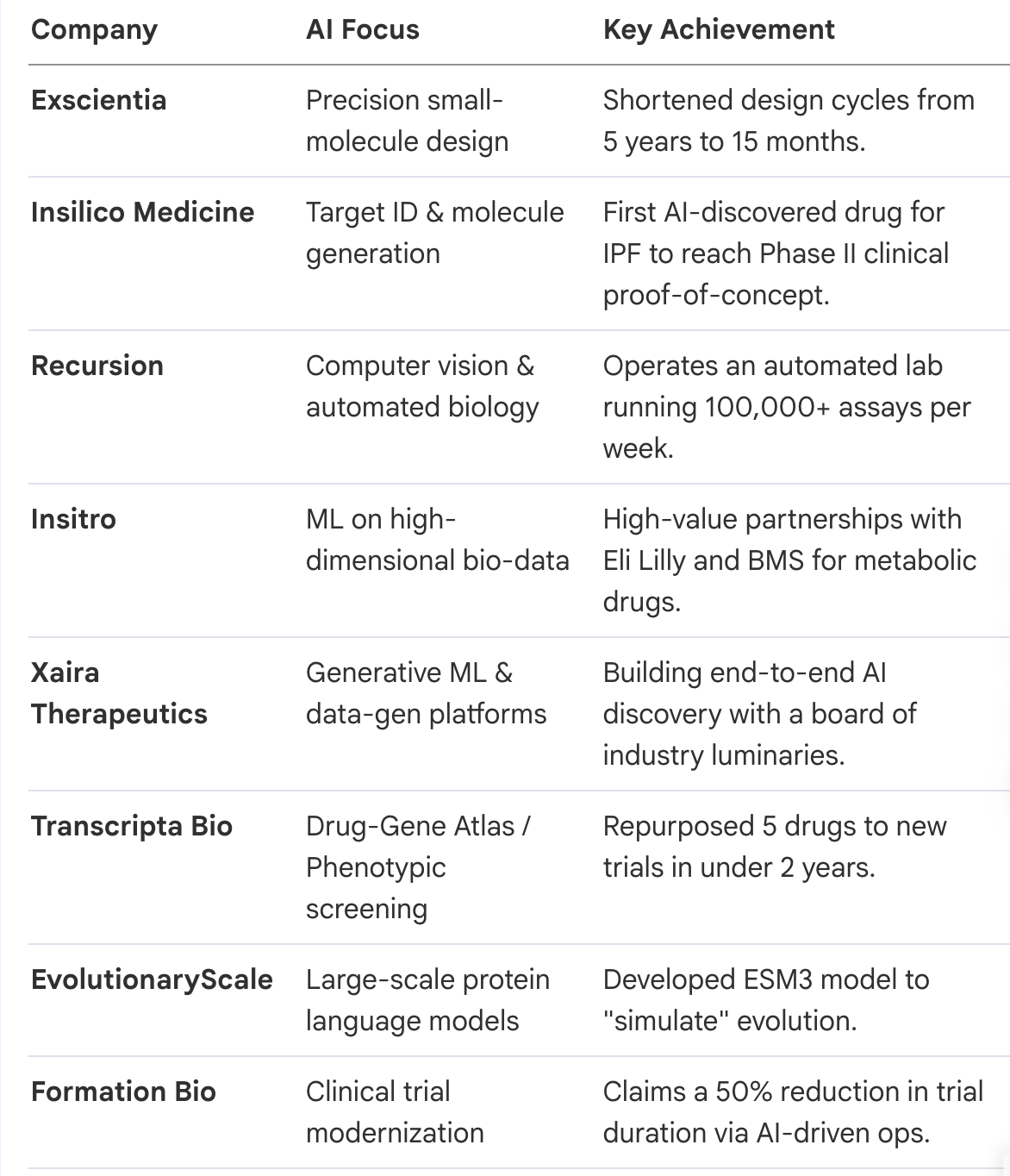
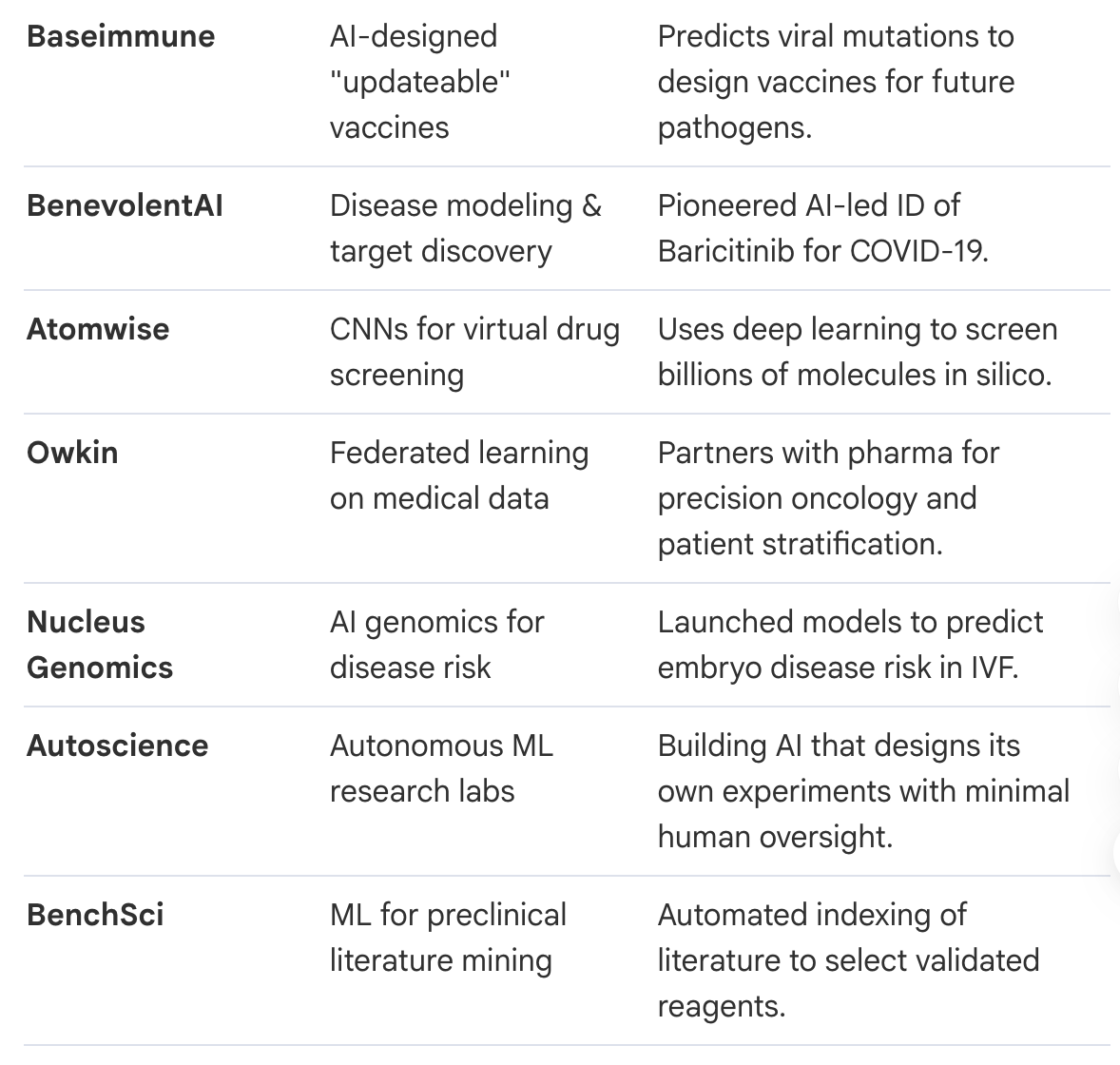
2.2. Which startups are addressing post-discovery bottlenecks like clinical trials and genetic risk?
Companies like Formation Bio and Nucleus Genomics are tackling the administrative and diagnostic bottlenecks that slow market entry. Formation Bio focuses on “clinical-trial modernization,” using AI to automate patient recruitment and regulatory filings. Their claim of a 50% reduction in trial duration has translated into massive economic value, evidenced by $2 billion in deals with industry giants like Sanofi and Eli Lilly. Crucially, the value in these deals was realized through clinical-trial speed-ups even for in-licensed drugs, rather than through AI-driven discovery itself.
2.3. How are “Generative Biology” and “Protein Engineering” firms like EvolutionaryScale differentiating themselves?
Firms like EvolutionaryScale are moving beyond small molecules to “Biology-as-Code.” Their ESM3 model, trained on over 3 billion protein sequences, allows for the design of novel proteins nature never produced. In a landmark case, they created “esmGFP,” a novel fluorescent protein, by effectively simulating 500 million years of evolution in a computational environment—generating a protein only 58% similar to its nearest natural relative.
As these startups mature from “discovery” to “clinical” stages, the focus shifts from capital scale to the underlying technical “black box” that allows them to interrogate biology with unprecedented resolution.
3. Computational Methodology: The Technical Stack
Modern drug discovery has transitioned from “virtual screening” (simple filters) to multi-modal data integration, where algorithms synthesize genomics, cellular imaging, and vast swathes of medical literature to find non-obvious therapeutic links.
3.1. How do “Signature-Based” methods like the Connectivity Map (CMap/LINCS) function?
Signature-based methods operate on the “anti-correlation” hypothesis. Researchers identify a “disease signature” (the specific genes that are over- or under-expressed in a sick cell). They then query databases like the Connectivity Map (CMap/LINCS)—which contains over 1.5 million drug-induced profiles. A critical technical lever is the LINCS L1000 assay, which measures 1,000 landmark genes and imputes the remaining transcriptome. This landmark-to-inferred model results in a 90% reduction in assay costs, allowing for high-throughput screening of transcriptional reversals across thousands of compounds.
3.2. What role do AlphaFold2 and Graph Neural Networks (GNNs) play in target-centric repurposing?
The methodology has evolved through four generations:
Generation 1: Classical ML using hand-engineered molecular descriptors.
Generation 4 (Current): Generative AI and Foundation Models. AlphaFold2 has expanded the tractable target space by providing 3D structures for 200 million proteins. Graph Neural Networks (GNNs), specifically those utilizing the Message-Passing Neural Network (MPNN) framework, are now the gold standard for binding affinity prediction. By representing molecules as graphs (nodes and edges), MPNNs capture complex molecular connectivity and atomic interactions far more effectively than traditional string-based models.
3.3. How does “Text Mining” transform the global patent archive into a biological database?
Natural Language Processing (NLP) uses Named Entity Recognition (NER) to identify drugs and genes, and Relation Extraction (RE) to determine how they interact. The Strategic Impact: This transforms the global patent archive into a queryable biological database. Researchers can identify compounds that were tested—but never marketed—in disparate therapeutic areas, revealing “white space” for new indications and providing a roadmap for in-licensing opportunities.
However, these computational predictions are merely speculative until they are anchored by a sophisticated legal strategy. In the pharma world, an unpatentable discovery is a discovery without commercial value.
4. Intellectual Property and Regulatory Strategy
In drug repurposing, the “Patentability Puzzle” arises because composition-of-matter patents are often already expired. Success depends on a secondary patent strategy to create new “exclusivity towers” around a known molecule.
4.1. What are the primary IP levers for repurposed assets?
Method-of-use patents: Protection for the new therapeutic indication.
Formulation patents: Protection for a new delivery method (e.g., oral to injectable).
Patient Selection/Biomarker patents: Protection for using the drug in a molecularly defined subgroup.
To defend these against “obviousness” rejections, firms use the “Unexpected Results” doctrine, providing data to prove the drug’s effect in the new indication was surprising and unpredictable based on prior knowledge.
4.2. How does the 505(b)(2) NDA pathway accelerate regulatory approval?
The 505(b)(2) pathway allows a sponsor to rely on existing safety data from a “Listed Drug.” This eliminates the need for redundant Phase I safety trials. Instead, the sponsor conducts a “Bridging Study” (PK/PD data) and an efficacy-focused clinical program. Critically, the FDA grants 3 years of exclusivity for new clinical investigations that were essential to the approval, providing a vital commercial window even if primary patents have expired.
4.3. Why is Orphan Drug Designation (ODD) considered the “Exclusivity Tower” for repurposing?
ODD provides 7 years of market exclusivity for rare diseases (under 200,000 US patients), independent of patent status.
Case Study: Revatio (sildenafil for pulmonary arterial hypertension) utilized ODD to protect the molecule even as the primary sildenafil (Viagra) patents expired.
Risk Mitigation: Strategists must account for Paragraph IV certification challenges. Generics may attempt “Skinny Labeling” (carve-outs), where they omit the patented repurposed indication from their label to bypass your exclusivity and flood the market for the original use, undermining the brand’s pricing power.
As we move from the legalities of market entry to real-world outcomes, the industry is finally seeing the first signals of clinical validation for AI-discovered targets.
5. Outcomes, Challenges, and Future Horizons
As of late 2025, the industry is reaching a critical “Clinical Proof-of-Concept” milestone. While dozens of AI-derived molecules are in Phase II trials, none have yet reached the market.
5.1. What is the significance of Insilico Medicine’s Rentosertib Phase IIa results?
Insilico Medicine provided the industry’s first clinical POC for an AI-identified target. In a Phase IIa trial for Idiopathic Pulmonary Fibrosis (IPF), their drug Rentosertib (a TNIK inhibitor) showed a mean lung function improvement (FVC) of +98.4 mL compared to a -20.3 mL decline in the placebo group. This validated the AI’s ability to not only design the molecule but identify a correct, novel biological target.
5.2. What are the three most common failure modes for computational repurposing?
Data Quality and Bias: Models trained on biased public datasets (e.g., over-representation of kinases) underperform on novel biology.
Target Exposure/Tissue Distribution: A drug may bind a target in a test tube but fail to reach therapeutic concentrations in the specific human tissue (e.g., failing to cross the blood-brain barrier).
Label Arbitrage by Generics: As noted, physicians may prescribe cheaper, off-label generics for the original indication, undermining the branded product’s ROI.
5.3. What emerging technologies will define the next generation of repurposing?
Quantum Computing: Expected in the 2030s to provide electronic-resolution binding predictions.
Single-Cell and Spatial Genomics: Leveraging the Human Cell Atlas to resolve exactly which cell types a drug affects, enabling “precision repurposing.”
Conclusion: The future of R&D is a “Human-in-the-Loop” model. AI will handle the massive scale of data mining and hypothesis generation, but human experts remain essential for mechanistic validation. To achieve high-confidence predictions, the industry is moving toward the REMEDi4ALL framework, advocating for “multi-platform consensus screening” where consistent results across multiple independent AI platforms become the gold standard for prioritizing assets.
Table of Contents with Timestamps
Introduction · 0:00
The opening theme and show description of Heliox: Where Evidence Meets Empathy.
The Wooden Chair Paradox · 0:25
A deceptively simple analogy introduces a maddening real-world mystery: why does adding better tools sometimes produce worse outcomes?
Eroom’s Law — Moore’s Law Written Backwards · 2:17
The counterintuitive law governing pharmaceutical R&D: since 1950, new drugs approved per billion dollars spent has been halving every nine years, despite massive technological advances.
The Broken Economics of De Novo Drug Discovery · 3:31
An examination of the traditional drug discovery model — 10–15 years, $2.6 billion, and a 90% clinical failure rate — and the human cost of a system that can’t afford to cure rare diseases.
The Back Door: Drug Repurposing · 5:49
Instead of building new molecules from scratch, repurposing asks whether existing approved drugs might cure entirely different diseases, dramatically improving timelines and survival odds.
Serendipity’s Greatest Hits · 8:03
The legendary accidental discoveries: sildenafil becoming Viagra, minoxidil becoming Rogaine, and the astonishing rehabilitation of thalidomide as a cancer therapy.
COVID-19 as a Forcing Function · 11:33
How pandemic urgency accelerated repurposing science — and how baricitinib went from a rheumatoid arthritis drug to an FDA emergency authorization in nine months.
The Reality Check: Soft vs. Hard Repurposing · 12:44
A Cambridge study breaks down the actual numbers — 67% success in closely related diseases, 9% in hard cross-domain repurposing — and reveals why the bottleneck is human cognitive limits, not chemistry.
Don Swanson and Undiscovered Public Knowledge · 17:36
The origin story of literature-based discovery: in 1986, a Chicago researcher used paper index cards to connect Raynaud’s disease and fish oil without ever touching a test tube.
The Rise of TechBio and Knowledge Graphs · 16:27
How the field of TechBio industrializes Swanson’s manual method using NLP, vector spaces, and three-dimensional biological knowledge graphs containing billions of verified relationships.
GANs and the Drug That Was Imagined · 22:02
InSilico Medicine uses generative adversarial networks to design a novel drug candidate for pulmonary fibrosis in 18 months at $2.6 million — a fraction of the traditional cost.
Co-Scientist: A Multi-Agent AI Coalition · 25:53
The May 2026 Google DeepMind paper introduces Co-Scientist — a coalition of specialized AI agents using a tournament-of-ideas framework, ELO ranking, and real-time database verification to generate and refine scientific hypotheses.
The Hallucination Problem — and How DeepMind Addresses It · 31:01
The single most dangerous risk of applying generative AI to physical science, and the architectural safeguards built into Co-Scientist to prevent confident falsehoods from reaching the lab.
Real Scientists, Real Wet Labs, Real Results · 33:45
Three case studies: Gary Peltz at Stanford (91% liver fibrosis blockage); Ritu Raman at MIT (AI as ALS collaborator identifying knowledge gaps); Omar Abudeya at Harvard (reversing cellular aging, months of analysis compressed to days).
Patent Thickets as Treasure Maps · 48:13
An ironic twist — the dense defensive patent fortresses built to hoard pharmaceutical knowledge are becoming the richest data sources for AI-powered repurposing discovery.
The Augmented Human · 51:08
The broader implication: AI does not replace scientists. It shifts the bottleneck upward — from data processing to strategic, ethical, and creative oversight.
N-of-One Medicine · 52:44
A vision of the near future: your genome sequenced, your unique disease profile fed into a Co-Scientist-like system overnight, a bespoke repurposed treatment found by morning.
The Warehouse Full of Furniture · 53:45
The closing synthesis: Eroom’s Law met its match not by building better tools, but by finally learning to see what was already there. The warehouse is full. We now have the flashlight.
Credits and Outro · 54:16
Production credits, recurring thematic frameworks, and an invitation to explore more at helioxpodcast.substack.com.
Index with Timestamps
4. Index
ALS (Lou Gehrig’s disease), 35:58
augmented human, 51:45
baricitinib, 12:22
blood viscosity, 18:43
blood-brain barrier, 5:14
Cambridge study (repurposing success rates), 14:22
ChEMBL (database), 32:09
clinical trials (Phase I), 7:06
CoScientist (DeepMind), 1:38, 25:53, 33:49, 48:43, 51:17, 52:19
collagen / hepatic stellate cells, 34:53
cytokine storm, 12:02
de novo drug discovery, 3:35, 11:41
DeepMind, 1:38, 25:53, 31:44, 34:02, 50:47
drug repurposing / repositioning, 6:07, 8:03, 11:33, 13:15, 14:22, 35:07
ELO rating system, 30:38
end-of-one medicine (N-of-one), 52:44
epigenetic reprogramming, 37:05
Eroom’s Law, 2:17, 45:00, 53:49
evolution agent, 32:47
failure rate (90%), 4:24, 4:32
fish oil (icosapentaenoic acid), 19:08, 19:45
Flynn, Ryan (RNA specialist), 36:42
GANs (generative adversarial networks), 22:43, 25:08
Gemini model, 26:27
generative AI, 22:02, 31:37
hallucination (AI), 31:10, 31:37
hard repurposing, 14:44, 15:08
hypothesis tournament, 30:24, 30:38, 32:47
InSilico Medicine, 22:02, 24:41
knowledge graph, 20:52, 21:05, 49:44
lab in the loop / self-driving labs, 34:10, 34:19
literature-based discovery (LBD), 17:16, 18:13, 19:25
liver fibrosis, 34:44, 35:11
meta-review agent, 33:05
minoxidil / Rogaine, 9:12, 50:29
Moore’s Law, 2:29, 2:37
multi-agent framework, 26:05, 26:33, 37:36
multiple myeloma, 11:16
NLP (natural language processing), 20:13, 20:27
Peltz, Gary (Stanford), 34:42, 35:27
pharmaceutical economics, 1:38, 4:02, 5:31
phocomelia / birth defects, 10:03
Raman, Ritu (MIT / ALS), 35:58, 36:42
Raynaud’s disease, 18:28, 19:45
reflection agent, 32:03, 32:24
rentocirtib (ISM001-055), 22:08, 24:23
repurposing (soft), 13:56, 14:22
$2.6 billion (development cost), 4:02, 5:36, 11:41, 24:41, 53:01
sildenafil / Viagra, 8:20, 9:06, 50:29
soft repurposing, 13:56, 14:30
Swanson, Don, 17:40, 19:45, 20:06, 50:35
TechBio, 16:34, 17:08, 22:00, 53:04
thalidomide, 9:42, 10:22, 10:42, 11:05
UniProt (database), 32:09
undiscovered public knowledge, 17:56, 18:03
wooden chair analogy, 0:25, 53:34
Poll
Post-Episode Fact Check
Claim: The number of new drugs approved per billion dollars of R&D spending has been halving roughly every nine years since 1950.
Verdict: Accurate. This is the quantitative definition of Eroom’s Law, first formally described in a 2012 Nature Reviews Drug Discovery paper by Scannell et al. The roughly nine-year halving period is the standard citation.
Claim: Bringing a single new drug to market takes an average of 10–15 years and costs $2.6 billion.
Verdict: Broadly accurate with caveats. The $2.6 billion figure derives from a widely cited 2016 Tufts Center for the Study of Drug Development study. It includes capitalized costs and the cost of failures, which is why the number is controversial — some researchers argue the true out-of-pocket cost is substantially lower. The 10–15 year timeline is standard industry consensus.
Claim: The clinical trial failure rate for drug candidates entering human trials is approximately 90%.
Verdict: Accurate. Multiple analyses, including work from the Biotechnology Innovation Organization, consistently place overall Phase I–III attrition at roughly 90%. Failure rates vary by therapeutic area.
Claim: Sildenafil was originally developed for angina and was repurposed as Viagra after male patients refused to return their pills.
Verdict: Accurate. This is well-documented pharmaceutical history. Pfizer researchers noted the side effect during trials for UK-92480 (angina indication) in the late 1980s and early 1990s.
Claim: Minoxidil was originally an oral antihypertensive before being repurposed topically as Rogaine after patients experienced hypertrichosis.
Verdict: Accurate. Minoxidil’s hair-growth side effect was observed during use as an oral drug for severe hypertension. Upjohn developed the topical formulation subsequently.
Claim: Thalidomide received FDA approval in 1998 to treat leprosy-associated skin lesions, and later became a therapy for multiple myeloma.
Verdict: Accurate. The FDA approved thalidomide (Thalomid, Celgene) in July 1998 for erythema nodosum leprosum. It later received approval as a treatment for newly diagnosed multiple myeloma in combination with dexamethasone.
Claim: Baricitinib, a rheumatoid arthritis drug, was flagged by algorithms and received FDA emergency use authorization for COVID-19 within approximately nine months.
Verdict: Broadly accurate. Baricitinib was identified computationally as a COVID-19 candidate early in the pandemic (published work includes BenevolentAI’s analysis, early 2020). The FDA granted emergency use authorization for COVID-19 in hospitalized adults in November 2020 — roughly 8–9 months after initial computational identification, depending on the reference point used.
Claim: A Cambridge study found soft repurposing has a 67% success rate; hard repurposing has a 9% success rate.
Verdict: Plausible and consistent with the literature, though the specific Cambridge study is not named. Multiple peer-reviewed analyses distinguish between same-indication-class and cross-indication repurposing with substantially different success rates. The specific figures (67%/9%) align with general published ranges; the precise study citation should be verified in the show notes.
Claim: InSilico Medicine identified rentocirtib (ISM001-055) as a candidate for idiopathic pulmonary fibrosis in 18 months at a cost of $2.6 million, synthesizing only 78 physical compounds.
Verdict: Accurate. InSilico Medicine published this data in Nature Biotechnology (2023). The 18-month timeline to preclinical candidate, the 78 synthesized molecules, and the $2.6 million discovery-phase cost are cited figures from that publication.
Claim: Google DeepMind published a paper in Nature in May 2026 titled “Co-Scientist: A Multi-Agent AI Partner to Accelerate Research.”
Verdict: As stated in the transcript, this is the core source document. The paper’s publication date and journal should be confirmed against the actual citation in the show notes.
Claim: Gary Peltz at Stanford tested a Co-Scientist-recommended repurposed drug on liver fibrosis cells and achieved 91% blockage of the scarring-linked response.
Verdict: Sourced directly from the DeepMind Co-Scientist paper (as described in the transcript). This is a primary source claim; the specific experimental data should be cited to the paper itself.
Claim: Ritu Raman at MIT works on ALS and described her experience with Co-Scientist as working with a genuine intellectual collaborator.
Verdict: Sourced from the DeepMind paper. Ritu Raman is a verifiable MIT researcher in bioengineering and mechanobiology; her work on neuromuscular disease is consistent with this description.
Claim: Omar Abudeya works on epigenetic reprogramming and said using Co-Scientist felt like having a team of 50 people.
Verdict: Sourced from the DeepMind paper. This specific quote and researcher should be cited to the primary paper for verification.
Overall fact-check rating: The episode’s major scientific and historical claims are well-grounded in verifiable published literature. The primary speculative element — the Co-Scientist paper and its real-world validation results — is sourced from a single primary document (the DeepMind Nature paper). Listeners are encouraged to read the primary source, linked in the show notes at helioxpodcast.substack.com.
Image (3000 x 3000 pixels)

Mind Map
Comic

Street Art

Infographics
